Large Language Models (LLMs) offer incredible potential for interacting with technology. But each LLM has its own strengths and weaknesses, shaped by its training data and architecture. Some excel at creative writing, weaving captivating stories and poems, while others are better at factual tasks like question answering or summarizing complex information.
Additionally, some LLMs are specifically trained to understand certain languages or dialects, while others are more proficient in specific domains or topics, like medicine or finance. These specialized LLMs can also be more cost-efficient, as they can be trained on smaller datasets and require less computational resources.
So, why would we want to use multiple LLMs in a single chat interface? By combining the unique strengths of different LLMs, we can create a significantly more versatile and powerful experience for users. Imagine being able to seamlessly switch between generating creative content, getting accurate answers to factual questions, and discussing complex topics in a specialized domain – all within one conversation. This not only enhances the user experience but also opens up new possibilities for how we interact with and utilize LLMs.
For this whole blog post, we’ll use Buildel, an open-source platform for creating advanced AI workflows. At the end of the post you will be able to build a multi LLM chat and expose it for your usage. Just like the one below.
It has two LLMs:
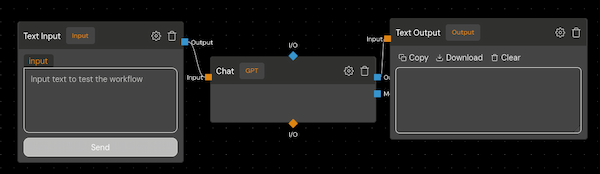
To understand the advantages of using multiple LLMs, let’s first look at a basic chat interface powered by a single model.
This simple question-answering system relies on a single LLM (in this case, GPT-3.5-turbo) to generate responses. The system message instructs the LLM to “be a helpful assistant, answer questions to the best of its ability, and admit when it doesn’t know the answer.”
While this basic chat interface can provide informative responses to a wide range of queries, it’s ultimately limited by the capabilities of the single underlying LLM. For instance, if the LLM isn’t specifically trained on a particular topic or language, its responses may be inaccurate or incomplete.
While the basic chat interface is a good starting point, we can further enhance its capabilities by integrating API tools. This allows the chat interface to access and utilize external data sources, providing more comprehensive and up-to-date information.
One approach is to leverage Retrieval-Augmented Generation (RAG). RAG models combine the power of LLMs with information retrieval techniques. In simpler terms, they can access and process relevant documents or data from external sources before generating responses.
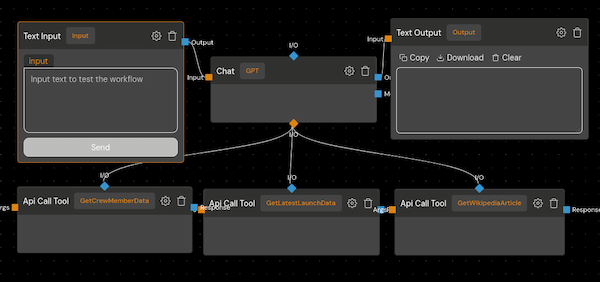
Let’s see how this works in practice. We can enhance our chat interface with access to the SpaceX API, enabling it to answer questions about SpaceX by directly retrieving information from the source.
As you can see, the chat interface can now provide detailed and accurate answers to questions about SpaceX launches, rockets, and other related topics. This is because the RAG model can access and process real-time data from the SpaceX API before formulating its response.
We can further expand the capabilities of the chat interface by integrating additional API tools, such as weather APIs, news APIs, or translation APIs. This would allow the chat to answer an even wider range of questions and provide diverse information. However, it’s important to note that incorporating multiple API tools also presents challenges. Requesting a completion requires including definitions for each API tool, which can increase response time and cost as the number of tools grows. Additionally, the bot may sometimes struggle to select the most appropriate tool for a given question.
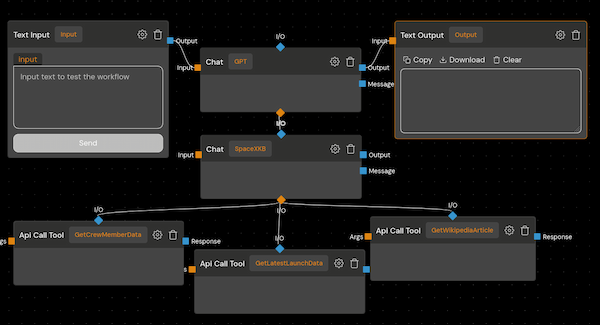
Taking the concept of enhanced functionality further, we can integrate multiple LLMs into the chat interface. This allows us to leverage the strengths of different models, creating a more versatile and powerful experience for users.
In this example, we’ll combine two LLMs:
By combining the general capabilities of GPT-3.5-turbo with Gemini 1.0-pro’s access to specialized knowledge, we create a chat interface that can seamlessly handle diverse topics and provide in-depth information when needed. This multi-LLM approach significantly enhances the user experience and opens up new possibilities for interacting with and utilizing LLMs.
Interestingly, we can further optimize this multi-LLM approach by considering the nature of the second LLM’s responses. Often, the specialized LLM provides answers that are comprehensive and self-contained, eliminating the need for follow-up questions. Taking this into account, we can configure the second LLM to operate without memory. This means it doesn’t retain past interactions, reducing its resource usage and making it more cost-efficient.
The integration of multiple LLMs within a single chat interface opens up exciting possibilities for the future of human-computer interaction. By harnessing the combined power of general and specialized language models, we can create chat experiences that are more versatile, informative, and efficient than ever before.
While challenges remain, such as optimizing cost and ensuring seamless integration of different models, the potential benefits are undeniable. As LLM technology continues to evolve, we can expect to see even more sophisticated and nuanced multi-LLM chat interfaces that revolutionize the way we communicate with machines and access information.
All the examples and concepts showcased in this post were created using Buildel, an open-source platform for building advanced AI workflows. Try it out and create your own multi-LLM chat interface.
If you liked the post you might also want to read:
← How 3000 people won in my self-hosted game